1. 如何用python将PDF转为TXT
所需依赖:pdfminer3k、python-docx
所需步骤:解析PDF、取出数据、保存为TXT/Word
遇到的坑:
- 最开始安装的依赖为pdfminer,而python环境为3.7,导致无法调用(并且包的依赖其实应该是install pdfminer3k才对),这里我一直无法理解的就是明明包名为pdfminer,但是安装却要是pdfminer3k,其他类似的很多,表示暂时还无法理解,所以每次都需要相应的依赖是个啥……
- Document无法引用,安装的docx不存在,哈哈,这个是因为之前用VS2017安装的docx里面引用了exceptions,python3.x版本移除了exceptions模块,但是docx包中引用了该模块,故有掉进去了,嗯嗯,在https://www.lfd.uci.edu/~gohlke/pythonlibs/ 安装新的python_docx‑0.8.10‑py2.py3‑none‑any.whl即可。
- 上面引用没问题后,下面一个坑好像就么得了,然后去理解包中使用的方法的含义吧——“努力、奋斗”
方法解读:
“窃”一个图: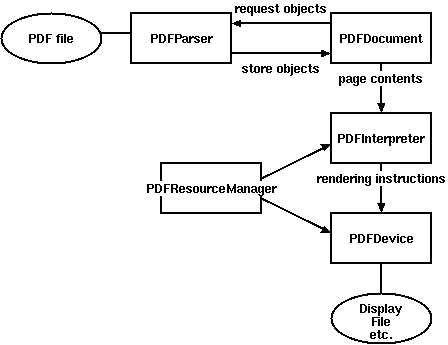
要解析PDF至少需要两个类:PDFParser 和 PDFDocument,PDFParser 从文件中提取数据,PDFDocument保存数据。另外还需要PDFPageInterpreter去处理页面内容,PDFDevice将其转换为我们所需要的。PDFResourceManager用于保存共享内容例如字体或图片。
Python os.listdir() 方法:1
2
3
4
5
6
7
8
9
10
11
12#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os, sys
# 打开文件
path = "/var/www/html/"
dirs = os.listdir( path )
# 输出所有文件和文件夹
for file in dirs:
print file
2. Let’s do it
PDF转TXT
1 | #!/usr/bin/env python |
PDF转Word
1 | import os |

